

This guide will compare and contrast these data integration methods, explain their use cases, and discuss how data virtualization can streamline pipeline development and management - or replace pipelines altogether.Īs enterprise data sources proliferated, information architectures fragmented into isolated data silos.

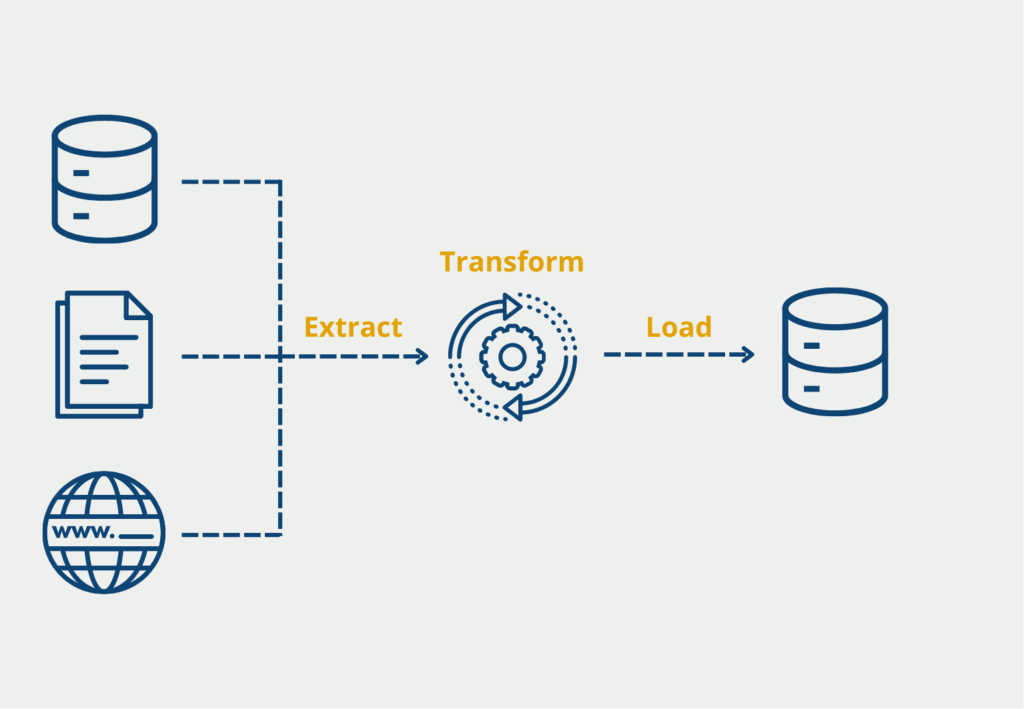
Load: The loading process deposits data, whether processed or not, into its final data store, where it will be accessible to other systems or end users, depending on its purpose.Ĭommonly used to populate a central data repository like a data warehouse or a data lake, ETL and ELT pipelines have become essential tools for supporting data analytics. Additional data processing steps may cleanse, correct, or enrich the final data sets. Transform: Data transformation involves converting data from its source schema, format, and other parameters to match the standards set for the destination. Extract: Data extraction is acquiring data from different sources, whether Oracle relational databases, Salesforce’s customer relationship management (CRM) system, or a real-time Internet of Things (IoT) data stream.